7.23
疑问:
1、官方解法2
https://leetcode-cn.com/explore/featured/card/bytedance/244/linked-list-and-tree/1040/
7.13
mysql锁
https://www.jianshu.com/p/13f5777966dd
一、行级锁:
分三类:记录锁、间隙锁、临键锁
加锁的场景:
共享锁
select … lock in share mode
排他锁
select … for update
update、delete、insert
1、记录锁
对某行进行加锁,如insert时,记录还不存在怎么办?会创建一个隐藏的聚簇索引,然后将其记录为锁定状态。
2、间隙锁
锁定一个范围,都是开区间
3、临键锁(next-key lock) 记录锁+间隙锁的组合
二、快照读&当前读
三、何为幻读
1、同一个事务,连续两次当前读,那么这两次当前读返回的是相同的记录(记录数量一致,记录本身也一致),第二次不会返回更多的记录(幻象)
2、如何解决幻读:间隙锁
因为光锁定记录无法确保不会有幻读情况的产生,根据B+树的性质,需要将匹配的记录之前最近的一条记录,匹配的记录之间,匹配的记录之后的最近一条记录,加三个间隙锁。避免了两次当前读会有幻读现象产生。
3、mysql RR级别下是否解决了幻读?
我认为解决了,在快照读的情况下,mysql通过MVCC来避免幻读。在当前读的情况下,mysql通过next-key lock来避免幻读。
四、加锁的场景
1、如果是RC隔离级别,正常状态下主键索引会加锁,如果二级索引的话,则二级索引会加锁,同时该索引对应的主键索引加锁,不满足条件的主键索引锁会被释放,即有两个锁。
2、如果是RR隔离级别,会针对记录加间隙锁,
疑问:
1、innodb_locks_unsafe_for_binlog作用
2、ICP(Index Condition Pushdown)机制了解
3、间隙锁到底怎么锁的,到底是不是前开后闭?
7.14
一、mvcc机制
数据的新增和删除是会维护一份版本号,记录了记录新增/修改时的版本号,删除的版本号,通过undolog可以找到数据之前的版本记录,RC隔离级别下,每次select都会发起一次快照读。而RR隔离级别下,只会记录第一次的快照读结果。
二、spring事务传播行为:
1、required 默认的传播行为,如果存在事务,则支持当前事务。若没有则开启一个新事务。
2、supports 如果存在一个事务,支持当前事务,如果没有事务,则以非事务状态执行
3、mandatory 强制的,有事务加入,当前没有事务,抛异常
4、require_new 总是开启新事务,当前有事务则挂起存在的事务
5、not_supported 以非事务执行,挂起存在事务
6、never 以非事务执行,若存在事务,抛出异常
7、nest 嵌套,若有事务则以嵌套事务执行,若没有类似required。
三、分库分表方案
why选择了分库?可扩展性更好,同时对单机性能要求也更低,因为多个库可以分布在多台机器上,分表则局限性较高。
分两类:
以jar包形式引入到项目中,如sharding-jdbc
以proxy层形式提供服务,如mycat
疑问:
1、深入理解何博士关于MVCC的内容。
2、死锁排查及检测实例了解,何登成的文章。
3、semi-consistent了解
7.17
一、seata事务模型
分为三个模块来处理全局事务和分支事务的关系及处理过程
1、Transaction Coordinator(TC): 事务协调器,维护全局事务的运行状态,负责协调事务的运行状态,驱动全局事务的提交或者回滚。
如示例代码中的seata-server部分。
2、Transaction Manager(TM): 事务管理器,控制全局事务的边界,负责开启一个事务,负责全局事务的提交或回滚的决议。
3、Resource Manager(RM): 控制分支事务,负责分支注册、状态汇报,接受事务协调器的指令,驱动分支事务的提交和回滚。
疑问:
1、mysql的XA事务
引入一个TM,负责子事务的管理。进行两阶段式的提交: prepare阶段、commit/rollback阶段
7.10
mysql中的锁:
一、各种锁:
1、共享/排他锁(Shared and Exclusive Locks)
2、意向锁
3、记录锁
4、间隙锁
5、临键锁
6、插入意向锁
7、自增锁
二、共享/排他锁
1、共享锁: select from t where id = ** lock in share mode;
2、排他锁: select from t where id = ** for update;
排他锁当insert、update、delete时,innodb会自动加上排他锁
三、意向锁
是表级锁,主要是当需要锁表时,快速告知其中是否有某行级锁的存在。否则需要一条条数据去遍历判断。
mysql锁分析:
https://www.jianshu.com/p/13f5777966dd
死锁分析
https://developer.aliyun.com/article/269774
https://juejin.im/post/5dac651451882529d1528e12
间隙锁
http://guitoo.cc/wordpress/2019/05/07/mysql%E6%98%AF%E5%A6%82%E4%BD%95%E5%A4%84%E7%90%86%E9%97%B4%E9%9A%99%E9%94%81%E7%9A%84%E5%8A%A0%E9%94%81%E8%A7%84%E5%88%99/
CQRS
https://www.martinfowler.com/bliki/CQRS.html
重构相关
https://github.com/phodal/migration
seata源码分析:
分布式事务实现原理:https://my.oschina.net/keking/blog/3011509
RM模块源码: https://mp.weixin.qq.com/s/EzmZ-DAi-hxJhRkFvFhlJQ
Fescar全局锁的理解: http://www.iocoder.cn/Seata/ZZ/Understanding-of-Fescar-lock-design-and-isolation-levels/
7.2
Map系
一、hashMap
1、1.8之前会死锁,why?
https://www.jianshu.com/p/1e9cf0ac07f4
由于扩容时是头节点插入,会导致死锁的发生。
如原槽位 A -> B -> C
线程1、2同时触发扩容
则线程1 先执行到 next = e.next,
线程2完成了扩容由于是头节点插入,扩容后的引用关系如 newTab2[i] = C -> B -> A
线程1继续进行扩容
1) newTab1[i] = A
2) e = next(B) , next = e.next(A) 则 newTab1[i] = B,
3) 接着处理A, 则 A.next = newTabi, newTab[i] = A, 则引用关系成了 B-> A -> B
则在get的时候,一旦获取该槽位的数据时,就会导致死循环,引起cpu 100%
2、1.7 1.8区别
1)1.7 是数组+链表 1.8 是数组+链表+红黑树
2)避免并发下的死锁,扩容时1.7用的头插法,1.8用的尾部插入
二、TreeMap
1、有序的map,key必须实现Comparable或者构造treeMap时,传入Comparator,否则会报错
2、与hashMap红黑树的区别,hashMap以hash作为顺序,treeMap是以key的顺序/comparator作为顺序
三、linkedHashMap
1、如何维持有序:entry额外维护了两个指针,before,after,来维护有序
2、LRU实现: 1、accessOrder设置为True 2、removeEldest实现,如设置个size 大于特定值返回true
mysql
一、事务的实现
1、redo log:
1)目的:
保证数据的持久化,避免脏页因为系统崩溃后,未来得及写入磁盘而丢失。
https://zhuanlan.zhihu.com/p/65811829
https://www.jianshu.com/p/57c510f4ec28
客户端进行数据操作时,都会经过buffer pool来处理,包括数据写入时也是,但是若每次写入都需要将数据刷到磁盘上,会触发N次随机IO。就需要redo log顺序写的机制记录每次数据页上发生的变化。
2)记录形式:
把第10表空间的第90号页面的偏移量为1024处的值更新为1
2、undo log:
1)目的:用户事务回滚及支持mvcc功能
2)事务回滚到前一版本的逻辑记录,记录的是逻辑语句。即insert,则undo是delete, update则是相反的update。
3、
1)为何要配套使用,若仅用redo log,则若事务涉及到很多记录,不敢刷脏页,因为事务失败无法回滚。
2)若仅有undo log, 则若脏页因系统宕机丢失了,则脏页上的数据无法恢复。
二、锁
mysql中的两种锁:lock、latch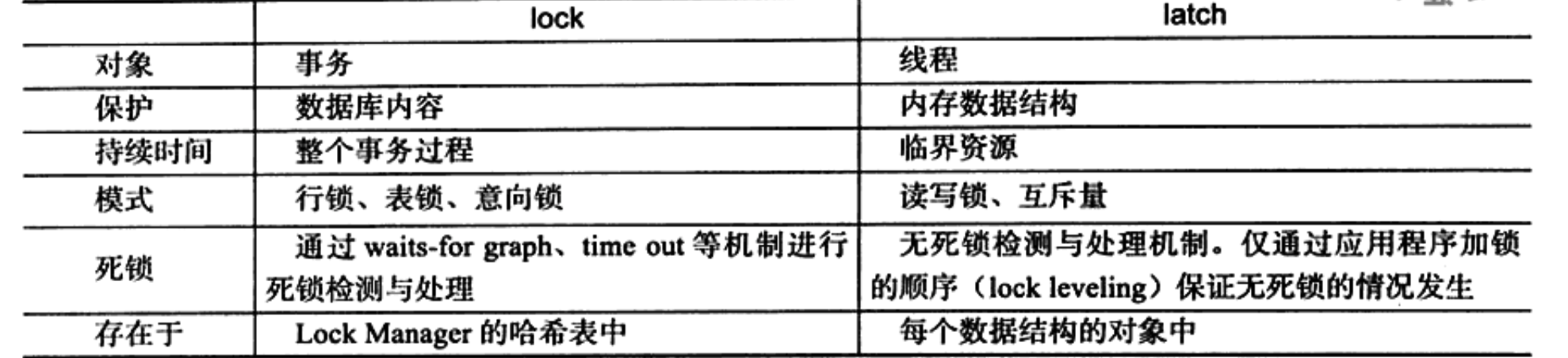
1、innodb两种标注行级锁:S Lock、X Lock
共享锁:允许事务读一行数据
排他锁:允许事务删除或更新一行数据
2、意向锁:
如果另一个任务试图在该表级别上应用共享或排它锁,则受到由第一个任务控制的表级别意向锁的阻塞。第二个任务在锁定该表前不必检查各个页或行锁,而只需检查表上的意向锁。
3、一致性读:利用多版本的某个时间点数据快照,达到不加锁处理select的效果
Repeatable read: 同一事务中读取的是该事务下第一次查询所建立的快照
Read Committed : 同一事务下的一致性读都会建立和读取此查询自己的最新快照
疑问:
1、hashMap put过程
6.28
一、共识算法(consensus algorithm)
1、cap中的一致性
任何一个读取返回新值后,所有后续读取(在相同或其他客户端上)也必须返回新值,类似volatile语义。
二、raft各部分
1、leader选举
2、日志复制
3、
6.15
一、GC之引用
1、referenceQueue
1.1、为了监控SoftReference/WeakReference/PhantomReference是否已被GC
1.2、为了替代finalize,之前释放的时机是交给了jvm来实现,可能会有并发释放啊等情况,不可控且不安全,当finalize时再次关联到强引用则无法被回收。而referenceQueue可以在gc之后,将该reference加入到queue中,可以通过remove在获取,再执行自定义的逻辑。
1.3、在GC发生之前放入queue中
2、虚引用 phantomReference使用场景:
比如记载一个很大的图片,当确认了图片已被GC后才允许继续加载图片,避免OOM。
二、GC收集器
1、cms(Concurrent Mark Sweep)收集器
1.1、收集过程
1)初始标记
stop the world,标记GC ROOT直接关联到的对象
2)并发标记
根据GC ROOT直接关联到的对象来进行并发递归进行标记
3)重新标记
stop the world,修正并发期间因用户程序继续运行导致标记产生变动的部分
4)并发清除
1.2、优点:低停顿
1.3、缺点:跟用户抢占cpu、无法收集浮动垃圾、会有很多内存碎片
2、G1收集器
2.1、收集过程
1)初始标记
2)并发标记
3)最终标记
4)筛选回收
3、对象分配过程
3.1、先在Eden区中分配,当Eden区没有足够的空间进行分配时,jvm将发起一次GC
3.2、大对象直接进入老年代
3.3、年龄达到一定值则晋升至老年代
疑问:
1、深入理解cms、G1
2、虚拟机调优
6.16
一、字节码:平台无关的中间码,为了支持java的跨平台支持,通过各种不同平台的jvm来将字节码翻译成平台相关的机器码。
二、类加载过程:
1、加载:将二进制流转成内存中class的数据结构
2、验证:字节码的规范检查、符号引用检查
3、准备:为static分配内存并设置变量类型的初始值
4、解析:符号引用转成直接引用(即静态绑定的过程)
5、初始化:clinit,给静态变量赋值
三、类加载器
双亲委派机制:向上查找,向下委托
递归操作:1、判断当前classLoader是否加载过 ->没加载过,是否有parent加载器,有则递归上述行为,没有则交给boot加载器递归上述行为 -> 尝试加载该类
四、各代垃圾收集器整理
1、垃圾收集器一览
1.1、年轻代: Serial、PraNew、Parallel Scavenge、G1收集器
1.2、老年代: Serial Old、Parallel Old、CMS、G1收集器
2、安全点:说白了就是一段引用关系不会发生变化的点
疑问:
1、锁升级过程
6.18
一、redisson的watchdog机制
为了避免持有锁的节点执行时间超过锁的过期时间,redisson提供了看门狗机制,在默认过期时间/3的频率会刷新过期时间,默认是30s。当节点挂了无法继续更新节点过期时间则自然会失效。
二、redis如何实现可重入的?
通过hash结构,key-value-count
通过count计数来控制锁的可重入
三、获取不到锁如何处理
通过一个本地的信号量,初始许可为0,acquire ttl时间,当锁释放了,则+1许可数量。避免出现同时唤醒多个线程竞争锁(羊群效应)。
四、公平锁如何实现
通过redis中内置的队列来达到这个效果
6.19
一、redLock
1、是为了避免发生单redis节点在failover时会发生解决不了的安全问题,redLock由N个完全独立的redis节点(通常5个)。
2、加锁步骤
2.1、获取当前时间
2.2、按顺序依次获取锁,获取锁的时候设置一个小的timeout时间,获取失败时继续获取别的节点
2.3、计算整个获取过程耗时,若<锁的有效时间且获取数量 >= N/2+1,则认为成功获取到了锁。
2.4、刷新锁的有效时间
3、存在的问题:
3.1、节点宕机导致的问题
1)客户端1锁住了A、B、C节点,D、E未获取成功
2)节点C崩溃,并未将C持久化下来,丢失了
3)节点B锁住了C、D、E,获取锁成功
故而需要设置延迟重启,重启间隔大于锁的有效时间。
3.2、客户端本身hang住导致的问题
1)客户端因为GC/网络原因,拿到第一个锁后hang住,直至锁过期了,才后续进行获取,计算出来的size满足锁的条件,导致可能同时两个客户端获取到锁。
即客户端1获取到 A、B、C,由于A获取到后停顿了一段时间导致A实际过期了,客户端获取到了A、D、E
加个单调递增的序号,数据库层面控制,当发现更低序号的请求时拒绝
3.3、对时钟一致性依赖程度较高
客户端1锁住节点A、B、C,时钟往前跳跃导致的节点C的锁快速过期,客户端2获取到了C、D、E
二、zk distributed lock
1、所有锁都放在一个节点下还是以锁为目录,在里头再具体排序,锁目录是怎么维护的?
可以新建一个以锁名命名的永久节点,里头加个前缀
2、获取逻辑:
2.1、先初始化锁目录,若没有新建永久节点
2.2、创建临时有序节点,判断该节点是否是children下第一个节点,是则获取锁
2.3、不是第一个节点则监听上一个节点,若监听到上一个节点被删除了说明锁获取成功,避免羊群效应
3、存在问题:
zk假心跳,网络不通等原因session过期,而实际仍在执行。另一个客户端也获取到了锁,则可能造成同时有两个锁
疑问:
1、zookeeper的watch机制,时间节点控制
提前watch好再判断exist即可
6.9
一、JVM各区域内存划分
线程私有:
1、程序计数器(Program Counter):
记录了线程当前正在执行的字节码,JNI的话则为undefined。
唯一一个无OutOfMemoryError情况的区域
2、虚拟机栈:方法执行的内存模型,由一个个栈帧组成,方法调用就是入栈,完成调用即出栈。
StackOverflowError: 栈内存不够了, -Xss可以设置栈的内存大小。
OutOfMemoryError: 内存分配会占用机器内存,当机器内存耗尽则会报内存溢出。
栈帧的组成:
2.1、局部变量表:this指针 -> 方法参数 -> 局部变量
2.2、操作数栈:虚拟机指令集设计一般分两类:基于寄存器的指令设计、基于栈的设计。JAVA是基于栈的,Android是基于寄存器的。基于栈的话更容易支持不同的平台,不会对cpu的寄存器做任何要求。
2.3、方法出口:
1)正常返回
2)异常返回
2.4、指向运行时常量池的常量引用:
2.4.1、字符引用与直接引用
字符引用:这个字符串包含足够的信息,如:“java/io/PrintStream.println:(Ljava/lang/String;)V”,可以在实际使用时,根据该字符串找到对应的方法。第一次使用时会替换为直接引用,不用再次搜索。
直接引用:就是偏移量,直接在类的内存中根据偏移量找到对应的方法字节码起始位置。
ref:https://www.zhihu.com/question/30300585
2.4.2、虚方法表: 每个类有个方法表,每个子类都有其父类方法表中国呢的所有方法。子类方法在方法表中的索引值,和它重写的父类方法索引值相同。当类加载时,动态绑定会将符号引用转成直接引用(类似方法表的索引值),静态绑定会直接指向具体的目标方法。实际调用时,获取调用方的实际类型及其对应的方法表,根据索引值找到实际的执行方法。
3、本地方法栈:执行Native方法用的
线程共享:
1、方法区/元数据:
JDK1.7叫方法区也叫永久代:用来存放虚拟机加载的类信息、常量、静态变量、编译后的代码。
JDK1.8中叫元数据区:MetaspaceSize 使用的是本地内存,不再与堆有关。同时字符串常量池移到堆上。
2、堆
从内存回收角度:新生代、老年代,为了更好的回收内存。
从内存分配角度(Thread Local Allocation Buffer 即线程本地分配缓存):
线程私有的分配缓冲区,并不是说这块内容是线程私有的,只是说线程分配角度来看是私有的,为了更快的分配内存,避免线程分配对象时针对同一块内存的竞争,��������������������������只有TLAB用完后,需要分配新的TLAB时,才需要同步锁定。
二、对象内存布局:对象头、实例数据、对齐填充
1、对象头:
1.1、运行时数据(64位):hashcode,gc分代年龄
1.2、类型指针(64位,未开启压缩指针):指向类元数据的指针,通过这个指针来确认这个类时哪个类的实例。
1.3、数组长度(32位):(若是数组的话)
2、压缩指针机制:
2.1、对象填充:对象的起始地址必须对齐至8的倍数,方便寻址。
2.2、字段对齐:为了让字段只出现在同一CPU的缓存行中,若不对齐则可能出现跨缓存行的字段。
2.3、压缩指针就是8字节为单位保存指针,即每个对象起始地址肯定是8的倍数,故而可以用每位实际地址/8来压缩其指针表示,堆的大小在4G ~ 32G之间可以用。
疑问:
1、TLAB
https://www.cnblogs.com/hollischuang/p/12453988.html
6.11
一、堆OOM
1、先确认是内存溢出还是内存泄漏
内存溢出:没有足够的内存分配
内存泄漏:申请内存后,没有释放已申请的内存。内存泄漏如果是频繁发生的话,最终会导致内存溢出。
二、GC相关
1、可达性分析:通过GC ROOT进行可达性分析,栈中引用对象,静态变量,常量引用对象
2、引用的分类:强引用、软引用、弱引用、虚引用
2.1、弱引用(weakReference)使用场景:当某些场景下,thread如线程池是复用的,由于threadLocalMap是线程特有的,一直在,则说明一直有强引用在,会导致即使栈上的threadLocal已经被销毁了,但是entry仍由于线程的关系无法被回收。
但是弱引用后,仅仅threadLocal被回收了,value并不会被回收,等于Entry中只是key没了,value还在。所以每次get或者set时遇到null的key,都会清理下value。
清理的时候还会进行重哈希,为何?因为使用的是开放地址法处理哈希冲突,所以每次查找到null的entry就停了,但是你清除entry的话,会导致后续的的entry查找中断,所以需要重新hash定位。
2.2、软引用(softReference)使用场景:适合第一次GC后仍旧没有足够的内存后才会收集掉。
三、hash冲突处理
1、拉链法:发生冲突时,类似hashmap的处理,适合节点比较多,可以通过较大负载因子带来的收益来抵消额外指针带来的空间浪费
2、开放地址法:类似threadlocal处理冲突的方式,比较怕冲突,因为一旦冲突厉害,元素较多,很有很多无意义的遍历。适合元素较小,负载因子设置较小的情况。
3、再哈希法:每级冲突都设置一个hash函数,但是增加cpu时间。
疑问:
1、一致性hash的深入了解
https://www.cnblogs.com/xrq730/p/5186728.html
2、内存泄漏理解,如何人工模拟内存泄漏
https://club.perfma.com/article/266960
内存泄露:应用占用cpu高,运行一段时间,频繁fullGC,但不马上抛内存溢出;
死锁:应用占用cpu高,gc无明显异常,jstack 命令可以发现deadlock
OOM: 这个看日志就能看出来,线程过多unable to create Thread,堆溢出:java heap space
某线程占用cpu高: 通过top命令查找java线程占用cpu最高的, jstack命令分析线程栈信息
3、线上响应慢原因排查
4、sql 两边执行计划不一致原因查询
5、treemap ceiling floor实现
一、JIT编译器相关
https://blog.csdn.net/qq_28674045/article/details/51896129
二、GC相关
1、Minor GC和Full GC的区别是什么?触发条件呢?:
https://www.zhihu.com/question/41922036/answer/93079526
2、关于CMS、G1垃圾回收器的重新标记、最终标记疑惑?:
https://www.zhihu.com/question/37028283/answer/78008095
3、主流的垃圾回收机制都有哪些?:
https://www.zhihu.com/question/32373436/answer/56461502
4、java的gc为什么要分代:
https://www.zhihu.com/question/53613423/answer/135743258
4.1、GC Root
比如栈上的引用,minorGC时,old gen代指向young gen的部分等。
6.9
1、JVM相关
https://www.artima.com/insidejvm/ed2/introarch.html
jvm内存空间划分
https://blog.jamesdbloom.com/JVMInternals.html
jvm相关问题
https://juejin.im/post/5d297a2e6fb9a07ee1695628
2、锁升级相关
https://juejin.im/post/5a5c09d051882573282164ae
3、JVM规范
https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.5.1
6.10
1、为什么移除永久代
http://openjdk.java.net/jeps/122
6.11
1、redis集群相关
分布式文件系统元数据服务器模型
http://yihongwei.com/2011/10/dist-filesystem-metadata-server/
2、P2P 网络核心技术:Gossip 协议
https://zhuanlan.zhihu.com/p/41228196
3、节点的存活检测,故障转移?
https://cloud.tencent.com/developer/article/1444057
4、jedis、lettuce
https://www.cnblogs.com/taiyonghai/p/9454764.html
6.17
1、分布式系统构建
https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
2、如果构建分布式锁
https://redis.io/topics/distlock
6.18
1、分布式数据库
http://dblab.xmu.edu.cn/post/google-bigtable/
6.22
1、分布式相关理论
http://baotiao.github.io/2017/11/16/choice-in-consensus/
https://www.cs.cornell.edu/fbs/publications/viveLaDifference.pdf
6.23
1、raft官网
https://raft.github.io/
2、线性一致性
https://zhuanlan.zhihu.com/p/42239873
3、一致性算法示意图
http://thesecretlivesofdata.com/raft/
6.1
网络层
一、MTU
1、不同数据链路中,MTU的大小也各不相同。当遇到需要传输数据大于MTU限制,会被分片传输。分片传输会加大路由器的负担,而且一旦某一分片异常没有到达,会导致整个IP数据报报废。
2、路径MTU
2.1、定义:
发送端主机到接收端主机之间不需要分片的最大MTU大小,即整个路由链路上中的最小MTU。然后主机根据MTU来提前分片后发送。避免在路由器上的分片处理,且可以在TCP中发送更大的包。
2.2、原理:
UDP中IP数据报设置禁止分片标志符,一旦路由器遇到需要分片才能处理的大包,不进行分片,而是将包丢弃,并返回ICMP不可大达消息将MTU值发回主机。主机根据MTU分好片后再循环之前的操作,直到没有收到任何ICMP。
TCP的情况下则是根据MTU计算出MSS长度,直接在TCP层就拆好包,避免了IP的分片。
二、IP层的协议
1、ARP:Address Resolution Protocol
通过广播根据IP获取MAC的协议
2、ICMP:Internet Control Message ProtocolAddress Resolution Protocol
检测网络是否通,例如PING命令,并告知错误原因等。